slow ai: ai that matches a human’s pace.
my mind digests information at a much slower pace than i’d like to believe. in college, i could breeze through a math lecture at 2x speed, convinced that i was following everything the professor was saying, only to stare blankly at a problem set not knowing where to begin.
math became very enjoyable for me once i slowed down and acknowledged that absorbing new information takes longer than i typically would anticipate. i would pick out a handful of high-quality problems, learn them inside and out, notice exactly where i got stuck, make a few logical leaps, and return to the same problem the very next day with a fresh pair of eyes. after a certain point, i realized that i didn’t actually need to consume that much information at all. understanding a new topic well1 had more to do with engaging deeply with a few core concepts.
i believe our brains are wired to get stuck on simple problems for extended periods of time. we might toil over the same problem for months – thinking about it in the shower, on the bus, from multiple different angles and perspectives. great scientists and artists often do so for years.
when information is hurled at us at 200 miles an hour – packaged in a fluent, convincing voice – the path of least resistance becomes to accept that information at face value, without taking the time to question, critique, verify, and make sense of it at our own pace.
ai can be used for slow thinking.
just as we now have widespread access to a tool for offloading thinking, we have an equally capable one for facilitating deep thinking, the type necessary to reach states of understanding and creativity: ai can follow a feyman-esque trail of questions, generate concrete examples on-the-spot, pull in documents, rubber-duck, and play devil’s advocate.
ethicist and cognitive scientist josh may offers a helpful rule of thumb for using ai in intellectual tasks: “you should use llms to generate inputs to your thinking, not outputs for others to read.”
designing slow ai.
lately, i’ve been thinking about ways to design ai to be more compatible with slow thinking.
first, an ai system should encourage the user to wrestle with the sequence of decisions that need to be made along the way to producing a final, polished response. just as understanding a mathematical proof requires wrestling with the underlying maze of failed paths along the way - one eventually feels solid about the sequence of logical steps that make a correct path correct - someone who receives an ai-generated response should be familiar with the major conceptual decisions behind the final response. decomposing the path of conceptual decision nodes that take questions to answers allows one to engage with alternative responses that could have been generated, reason through why those responses may have been valid (or invalid), and generalize those insights into future questions.
to test out this new mode of human-ai interaction, we created an interface that lays bare the messy conceptual roadblocks – the conflicting assumptions, interpretations, and frameworks – that shape an ai’s final response. the interface was a first attempt at allowing users to work through a space of possible decisions and resulting outputs, in the form of an interactive decision tree. confronted with a multiplicity of decision points, participants of our study felt a stronger sense of ownership over the final llm-generated responses. when compared to a traditional linear chat interface, users were surprised to find how long it took them to work through just one response,2 and how much they learned from the differing viewpoints along the way. our design draws inspiration from the concept of multiverse analysis, a scientific method that specifies and runs a set of data-analytical choices, reporting results for each.
second, instead of generating standalone responses, an ai system could present responses in the form of deliberations between different parties of generative agents. a discourse-style interface could surface the hidden assumptions and tradeoffs underlying complex, multiperspective problems. simply reframing the response as a debate may be enough to invite users to read as critics rather than recipients.
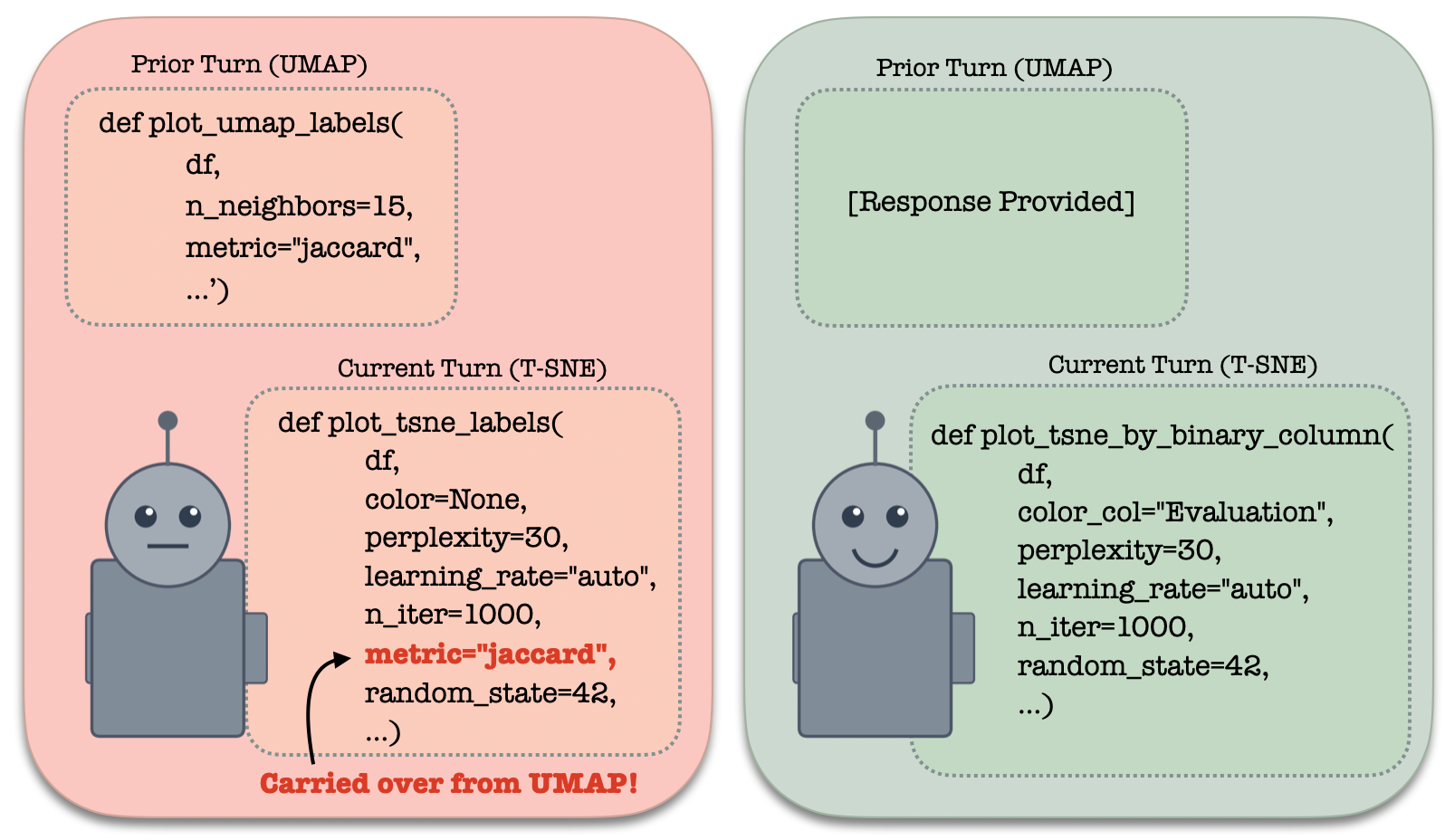
third, ai memory should be designed to prevent hidden assumptions from quietly accumulating in the context window. in recent work, we find that, as chat histories progress, models tend to get caught in old pieces of code (see figure 2) or vestiges of earlier responses that are no longer relevant. this problem of models becoming “more repetitive, and sometimes subtly wrong” as chat histories progress is a familiar headache. rather than linearly accumulating a full conversation transcript in context – tunnel-visioning the model with past lines of reasoning – we can design smarter, more structured ways to condition on the past. one way is to create a wide-angled view of chat history, representing past conversations as knowledge graphs. the model then conditions only on a high-level summary of the past, just enough to guide retrieval, while seeing the full conversation details when they become relevant.
finally, the system should respect that not every human problem deserves to be touched by an ai. in the mid-70’s, joseph weisenbaum’s computer power and human reason warned against consulting machines on tasks that require deeply human traits like empathy and wisdom. thus, we can design tools to encourage users to reflect on their boundaries with ai. to test this out, we developed a chrome extension which allows users of chat interfaces to define (by placing a pin in a quadrant graph) how much involvement they’d like an ai assistant to have in different areas of their work and life - from direct, concrete responses to reflective questions thrown back to the user. based on the user’s preferred boundaries, the tool produces a memory file that users can upload to a chat interface to guide the ai’s level of involvement.
dangers of the growing culture of fast ai.
i worry that the culture surrounding autonomous ai is self-reinforcing: the less we engage, the harder it is to find our ways back to engaging.
when information is handed to us already distilled and neatly packaged, the line between our own understanding and ideas introduced by an ai agent begins to blur. without giving ourselves the time to think critically about what we are receiving, we risk drowning out our own voices. to make matters worse, post-training pipelines have been shown to incentivize agents to steer user behavior toward states that are easier to satisfy. indeed, claude user trends show that disempowerment patterns in real-world llm usage are growing over time. to date, the human line project has documented almost 300 cases of ai psychosis.
interestingly, recent work on self-distillation has shown that llms learn better and forget less when they explain new concepts to themselves. rather than feeding the model content it cannot relate to (e.g., off-policy expert demonstrations), having the model explain the concept in its own words allows it to fold information into its pre-existing knowledge in a more sturdy way. just like machines, humans are better able to digest new knowledge when they carry a self-awareness about where their current understanding begins and ends.
so, while it is useful to spawn an agent to speed up work that we wouldn’t gain much from doing ourselves (e.g., writing plotting code), we should be more selective in choices to outsource our thinking during processes of knowledge creation. a key question here lies in when to speed up and slow down. while ai no doubt provides incredible “boosts” of speed when used in the right places at the right times, operating at such high speeds also makes steering the direction of knowledge work much more difficult. without the time to properly digest information at a human speed, it is easy to fall into the trap of spending weeks down unproductive rabbit holes - circling around and missing the right solution (or even the right questions).
amidst a culture of fast ai, it is worth leaning into the slow-thinking mind, the one that was wired to get caught up in simple problems over extended periods of time. indeed, at the current speed of ai progress, our capacities for slow, deliberate thinking may turn out to be our defining superpower.
this post took shape through productive discussions with andre ye, mitchell gordon, marwa abdulhai, andy liu, omar khattab, smitha milli, sana pandey, deb roy, philippe laban, tamara broderick, and other wonderful folks at iclr 2026.